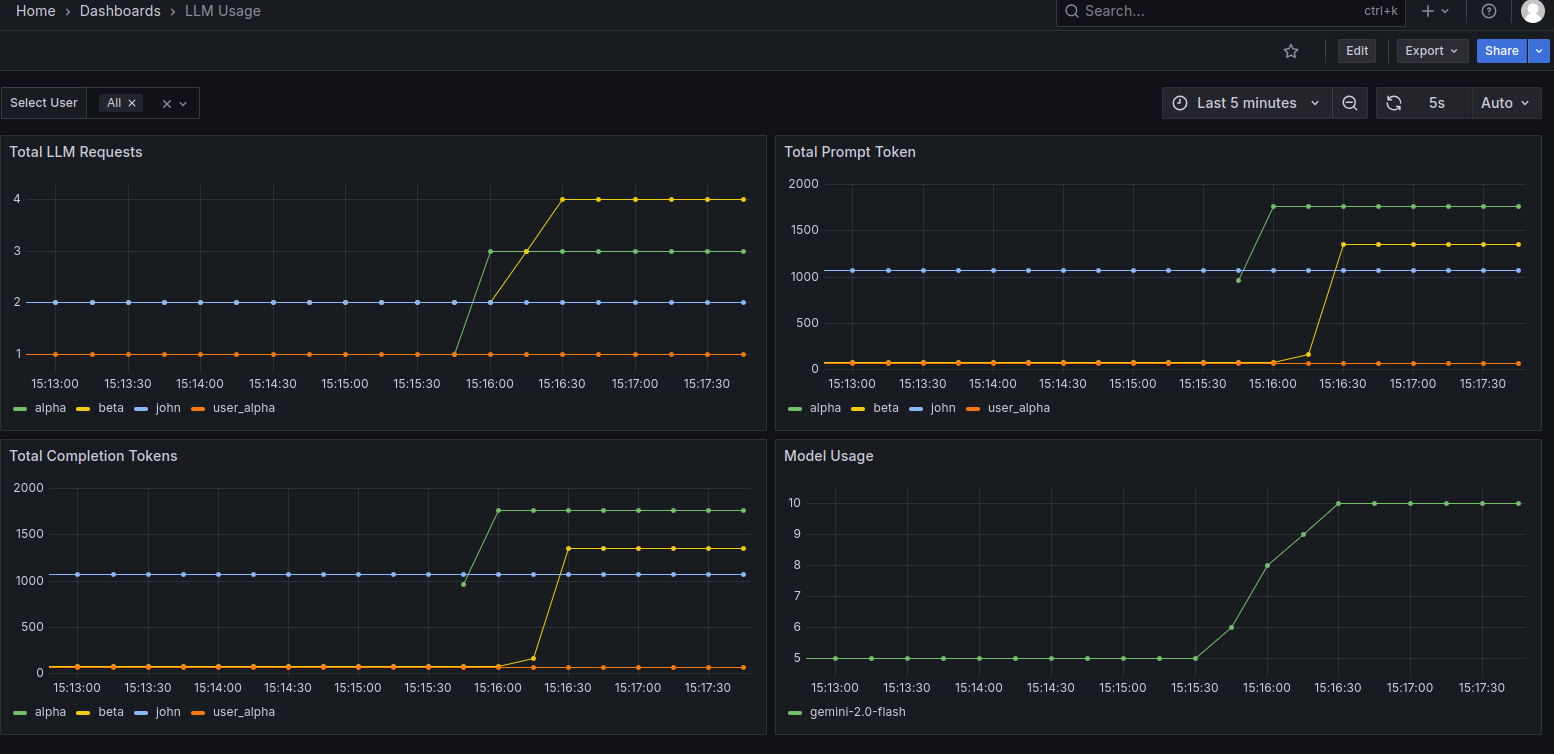
HTTP POST를 사용한 사용자별 LLM 사용량 대시보드 구축
명령어 사용
curl -X POST -H "Content-Type: application/json" -d '{
"user_id": "user id changeme",
"prompt": "question changeme",
"model_name": "gemini-2.0-flash"
}' http://domain changeme/ask_llm:5000
app.py
Python
import os
import time
import logging
import sys
print("--- app.py script started ---", file=sys.stderr)
sys.stdout.flush() # 버퍼 비우기
from prometheus_client import Counter, Histogram, start_http_server
from flask import Flask, request, jsonify
from openai import OpenAI # litellm 프록시와 호환되는 OpenAI 클라이언트 사용
# --- 로깅 설정 ---
# 콘솔에 로그를 출력하도록 설정
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')
logger = logging.getLogger(__name__)
# --- 1. Prometheus 메트릭 정의 ---
llm_requests_total = Counter(
'llm_requests_total',
'Total LLM API requests by user',
['user_id', 'model_name', 'status']
)
llm_prompt_tokens_total = Counter(
'llm_prompt_tokens_total',
'Total prompt tokens consumed by user',
['user_id', 'model_name']
)
llm_completion_tokens_total = Counter(
'llm_completion_tokens_total',
'Total completion tokens generated for user',
['user_id', 'model_name']
)
llm_response_time_seconds = Histogram(
'llm_response_time_seconds',
'LLM API response time in seconds',
['user_id', 'model_name'],
buckets=[0.1, 0.25, 0.5, 1.0, 2.5, 5.0, 10.0, float('inf')]
)
# --- 2. Prometheus 메트릭 서버 시작 ---
def start_prometheus_exporter(port=8000):
try:
start_http_server(port)
logger.info(f"Prometheus exporter started on port {port}. Access at http://0.0.0.0:{port}/metrics")
except Exception as e:
logger.error(f"Failed to start Prometheus exporter: {e}", exc_info=True)
# 익스포터 시작 실패는 치명적일 수 있으므로 앱 종료 고려
sys.exit(1)
LITELLM_PROXY_URL = os.getenv("LITELLM_PROXY_URL")
if not LITELLM_PROXY_URL:
logger.error("LITELLM_PROXY_URL environment variable is not set. Exiting.")
sys.exit(1) # 환경 변수 없으면 종료
LITELLM_PROXY_AUTH_KEY = os.getenv("LITELLM_PROXY_AUTH_KEY")
if not LITELLM_PROXY_AUTH_KEY:
logger.warning("LITELLM_PROXY_AUTH_KEY environment variable is not set. "
"If litellm proxy requires authentication, this will fail.")
LITELLM_PROXY_AUTH_KEY = "changeme" #*****************
try:
litellm_client = OpenAI(
api_key=LITELLM_PROXY_AUTH_KEY, # 실제 litellm 프록시 인증 키 (더미 아님!)
base_url=LITELLM_PROXY_URL,
timeout=60.0 # 타임아웃 설정 추가
)
logger.info(f"OpenAI client initialized for litellm proxy at {LITELLM_PROXY_URL}")
except Exception as e:
logger.error(f"Failed to initialize OpenAI client for litellm proxy: {e}", exc_info=True)
sys.exit(1) # 클라이언트 초기화 실패 시 종료
# --- 4. LLM 호출 함수 (litellm 프록시를 통해) ---
def call_llm_with_metrics(user_id: str, prompt: str, model_name: str = "gemini-2.0-flash") -> str:
start_time = time.time()
request_status = 'success'
prompt_tokens_consumed = 0
completion_tokens_generated = 0
response_content = ""
logger.info(f"Processing LLM request for user '{user_id}' with model '{model_name}'")
logger.debug(f"Prompt: '{prompt[:50]}...'") # 긴 프롬프트는 잘라서 로깅
try:
response = litellm_client.chat.completions.create(
model=model_name,
messages=[
{"role": "user", "content": prompt}
],
user=user_id # litellm에 user 정보를 전달 (로그/추적 용도)
)
logger.info(f"Received response from litellm for user '{user_id}'")
logger.debug(f"Raw response: {response.model_dump_json()}") # 응답 전체 JSON 로깅
response_content = response.choices[0].message.content
logger.info(f"Extracted response content: '{response_content[:100]}...'") # 추출된 content 로깅
if response.usage:
prompt_tokens_consumed = response.usage.prompt_tokens
completion_tokens_generated = response.usage.completion_tokens
logger.info(f"Tokens consumed (P/C): {prompt_tokens_consumed}/{completion_tokens_generated}")
else:
logger.warning("Usage metadata not available from litellm proxy response. Falling back to estimation.")
prompt_tokens_consumed = len(prompt.split()) # 단순 추정
completion_tokens_generated = len(response_content.split()) # 단순 추정
except Exception as e:
request_status = 'failure'
logger.error(f"LLM request failed for user '{user_id}' with model '{model_name}' via litellm: {e}", exc_info=True)
# 예외 발생 시, 사용자에게 에러 메시지를 반환
response_content = f"Error processing request: {str(e)}"
finally:
duration = time.time() - start_time
logger.info(f"Request for user '{user_id}' completed in {duration:.2f} seconds with status: {request_status}")
# --- 메트릭 업데이트 ---
llm_requests_total.labels(user_id=user_id, model_name=model_name, status=request_status).inc()
llm_response_time_seconds.labels(user_id=user_id, model_name=model_name).observe(duration)
if request_status == 'success':
llm_prompt_tokens_total.labels(user_id=user_id, model_name=model_name).inc(prompt_tokens_consumed)
llm_completion_tokens_total.labels(user_id=user_id, model_name=model_name).inc(completion_tokens_generated)
return response_content
# --- Flask 앱 설정 ---
app = Flask(__name__)
@app.route('/ask_llm', methods=['POST'])
def ask_llm():
data = request.json
user_id = data.get('user_id', 'anonymous_user')
prompt = data.get('prompt')
model_name = data.get('model_name', 'gemini-2.0-flash')
if not prompt:
logger.warning("Received request with missing prompt.")
return jsonify({"error": "Prompt is required"}), 400
try:
response_text = call_llm_with_metrics(user_id, prompt, model_name)
return jsonify({"user_id": user_id, "model": model_name, "response": response_text})
except Exception as e:
logger.critical(f"Unhandled exception in /ask_llm route: {e}", exc_info=True)
return jsonify({"error": "Internal server error"}), 500
@app.route('/health')
def health_check():
logger.info("Health check requested.")
return "OK", 200
# --- 애플리케이션 실행 ---
if __name__ == "__main__":
# 백그라운드에서 Prometheus exporter 시작
start_prometheus_exporter(port=8000)
# Flask 앱 시작
logger.info("My LLM Backend App starting on port 5000.")
app.run(host='0.0.0.0', port=5000)
Dockerfile
Dockerfile
FROM python:3.9-slim-buster WORKDIR /app COPY requirements.txt . RUN pip install -r requirements.txt COPY . . EXPOSE 8000 EXPOSE 5000 CMD ["python", "app.py"]
requirements.txt
requirements.txt
flask openai prometheus_client google-generativeai
docker-compose.yml 추가
llm_backend_app:
build: ./llm_backend_app
container_name: llm_backend_app
restart: always
ports:
- "5000:5000" # 백엔드 앱의 API 포트
- "8000:8000" # 백엔드 앱의 Prometheus 메트릭 포트
environment:
LITELLM_PROXY_URL: "http://litellm:4000/v1"
LITELLM_PROXY_AUTH_KEY: ${LITELLM_PROXY_AUTH_KEY}
depends_on:
- litellm
prometheus.yml 추가
global:
scrape_interval: 15s
scrape_configs:
- job_name: 'llm-backend-app'
metrics_path: '/metrics'
static_configs:
- targets: ['llm_backend_app:8000']
Dashboard Report